You can run multiple MetaDefender MFT High Availability Controller™ instances behind a load balancer to improve the availability of your application.
In a simple deployment with only one MetaDefender MFT HA Controller™ instance, if that instance stops responding — due to a crash, network issue, or maintenance — the entire application becomes unavailable and users cannot reach your service.
By deploying multiple MetaDefender MFT HA Controller™ instances and placing a load balancer in front of them, you introduce redundancy and remove this single point of failure.
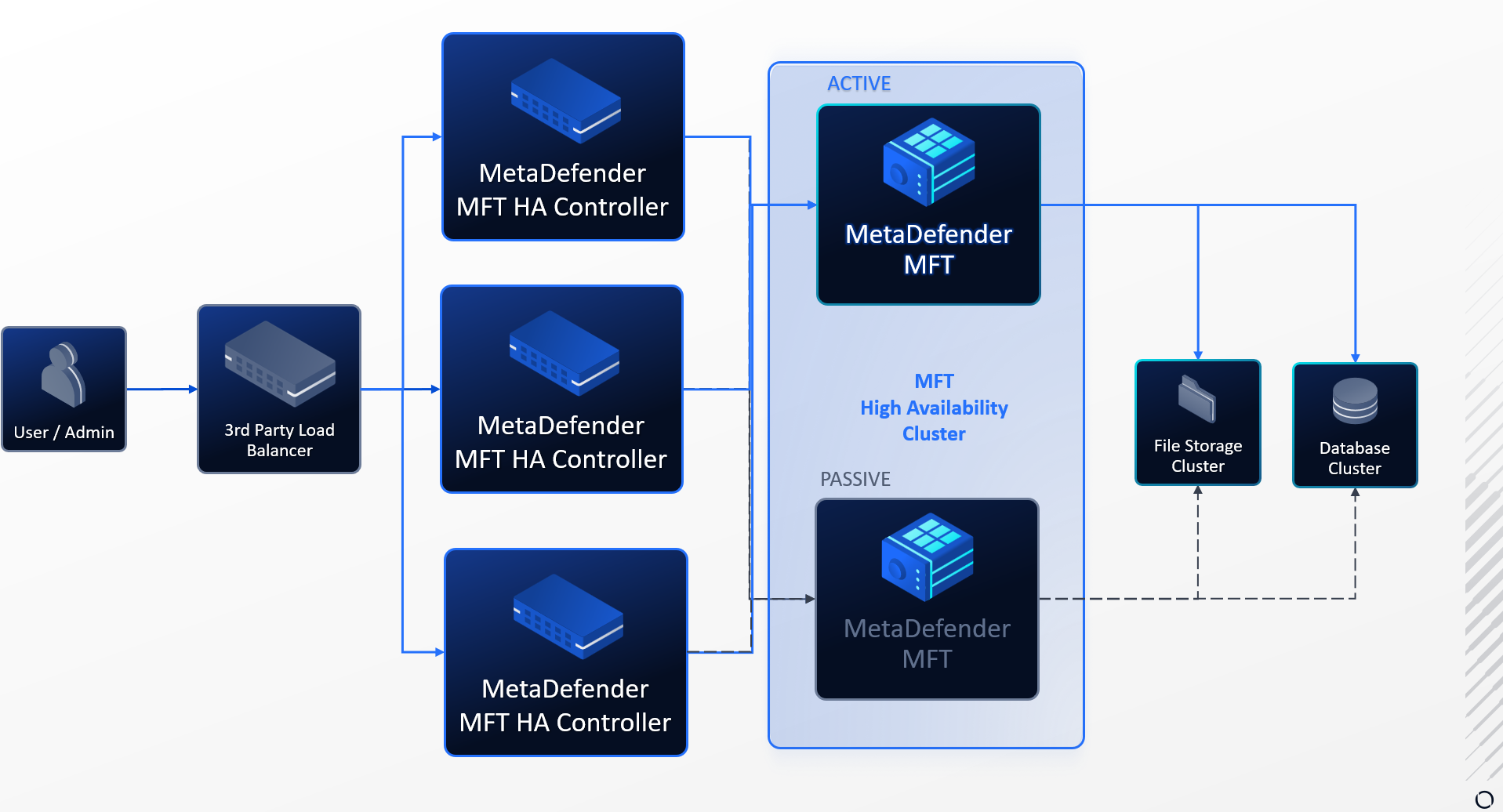
The load balancer continuously performs health checks on each MetaDefender MFT HA Controller™ instance and routes incoming user requests only to healthy ones. If one of your application instances becomes unreachable or fails its health check, the load balancer automatically stops sending requests to that instance and distributes traffic among the remaining healthy instances.
This means that the failure of any single MetaDefender MFT HA Controller™ instance does not bring your whole system down, the application continues responding to user requests without interruption.
You can find more information about MetaDefender MFT HA Controller™ health checks here.
MetaDefender MFT HA Controller™ roles
Each HA Controller instance operates in one of two roles: Leader or Follower.
Leader
At any given time, exactly one MetaDefender MFT HA Controller™ acts as the Leader. The Leader has two responsibilities:
- The Leader is the only node allowed to perform control actions on MetaDefender® MFT Services, such as activating or deactivating nodes. This single-leader model ensures that only one MetaDefender MFT HA Controller™ modifies shared state at a time, preventing conflicting operations and race conditions (for example, multiple nodes attempting to activate or deactivate the same service simultaneously).
- In addition to its coordination role, the Leader continues to proxy user requests just like any other MetaDefender MFT HA Controller™. It is not removed from traffic handling and remains part of the load-balanced request path.
Followers
The remaining HA Controller instances operate as Followers, followers has the following responsibilities:
- Proxy user requests
- Participate in leader election
- Monitor the Leader’s health
- Are ready to take over if the Leader becomes unavailable
If the current Leader fails, the Followers automatically initiate a new election to select a replacement.
Why at Least Three HA Controllers Are Recommended
Leader election is performed using the Raft consensus algorithm, which requires a majority (quorum) of nodes to agree in order to elect or maintain a Leader.
This requirement directly impacts how fault-tolerant your cluster can be:
- With 2 MetaDefender MFT HA Controller™, a majority is 2. If one instance fails, the remaining node cannot form a quorum. Without quorum, the cluster cannot elect or maintain a leader, and control actions (such as MetaDefender® MFT failover) cannot proceed. This behavior is intentional, Raft prefers availability loss over data corruption. Allowing a single remaining node to continue operating would risk split brain, where two isolated controllers might both believe they are authoritative and issue conflicting control decisions.
- With 3 MetaDefender MFT HA Controller™, a majority is 2. If one instance fails, the remaining two can still agree on a leader and continue normal operation — including managing control actions and proxying requests.
Running at least 3 MetaDefender MFT HA Controller™ ensures that the cluster can tolerate the failure of one instance while still electing or maintaining a leader, enabling high availability and reliable failover behavior.