Service failure
The MetaDefender MFT HA Controller™ periodically initiates health checks on each MetaDefender® MFT instance; if a service is found unhealthy, the controller will trigger a failover to the other node.
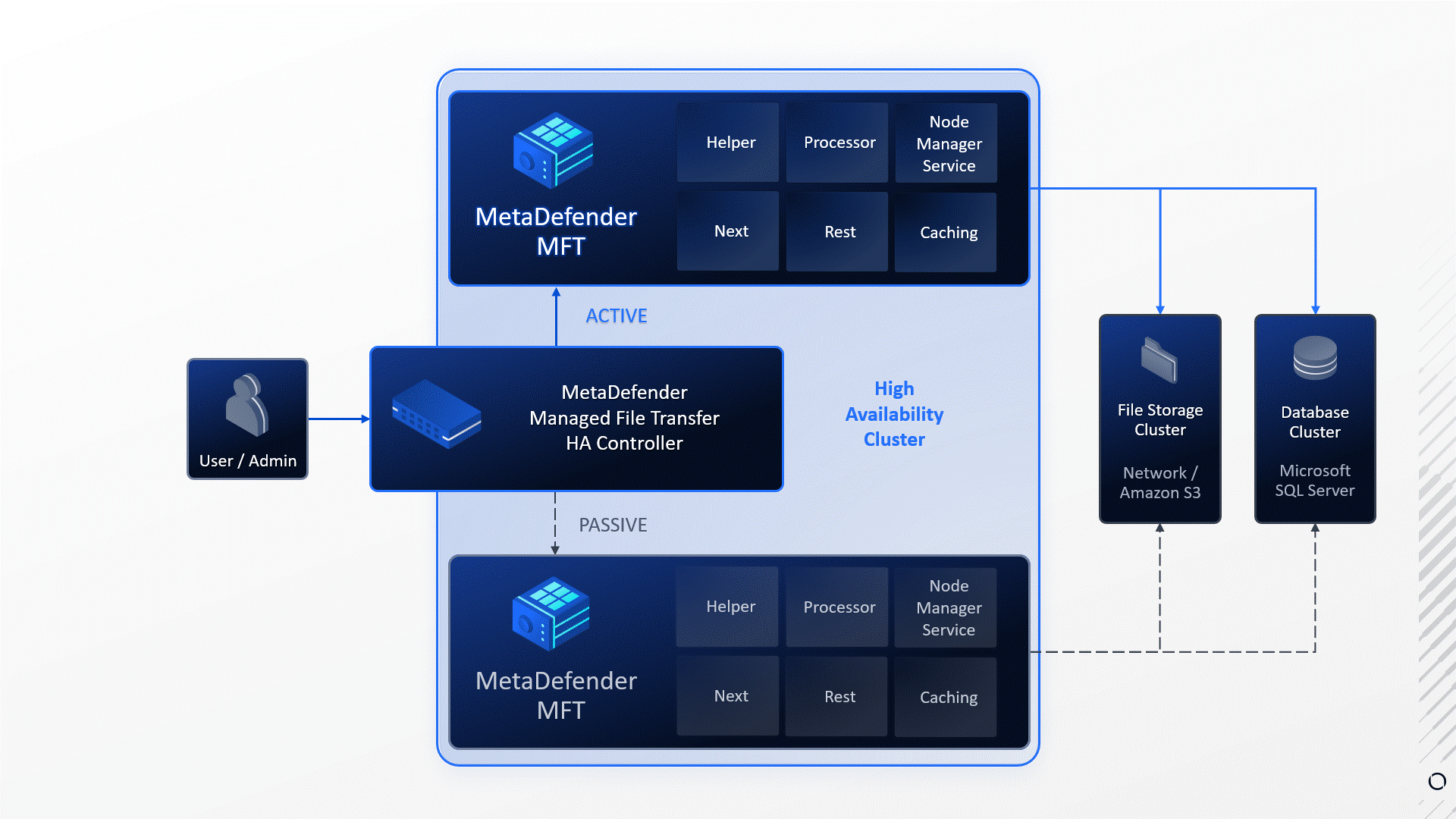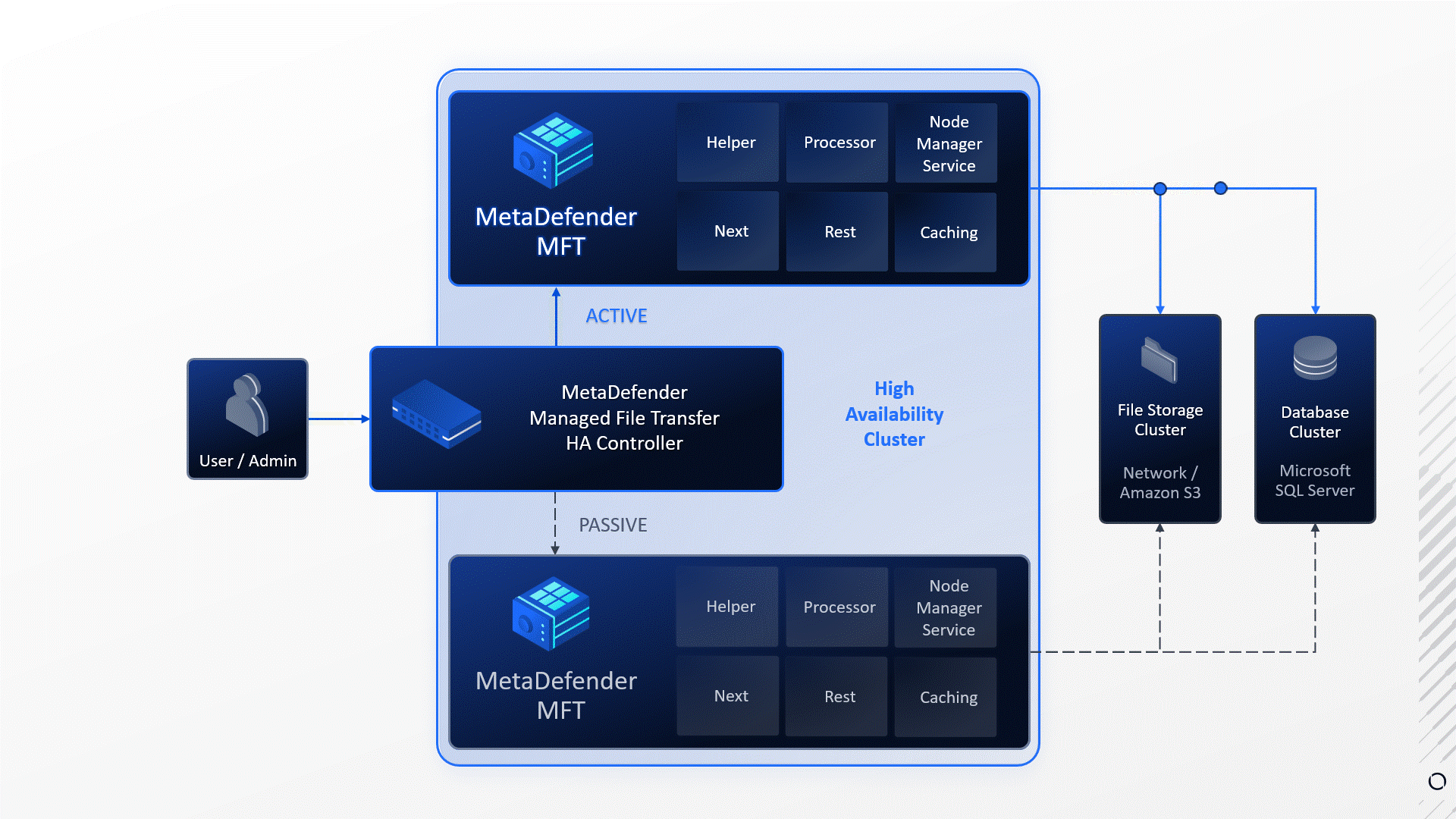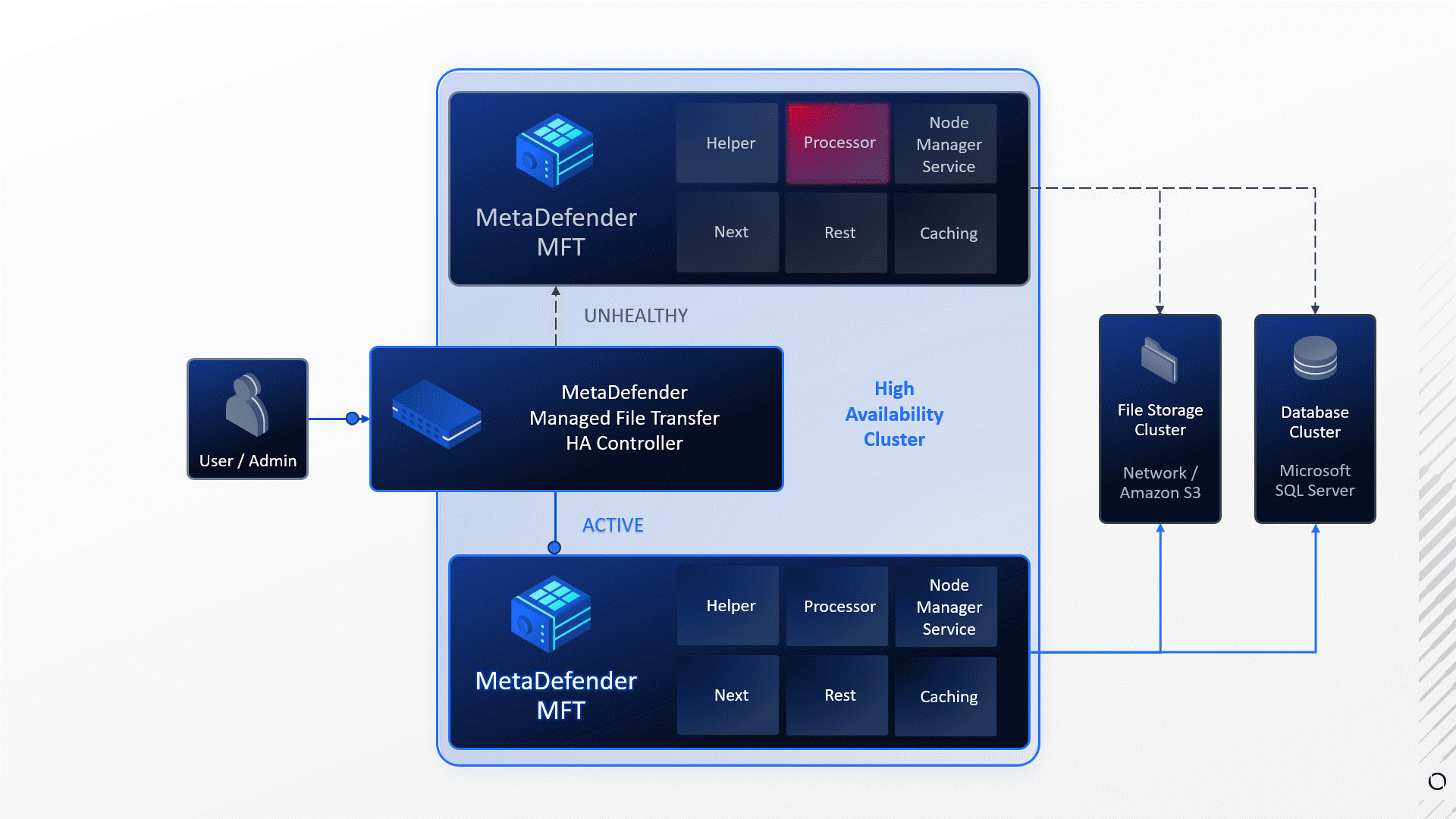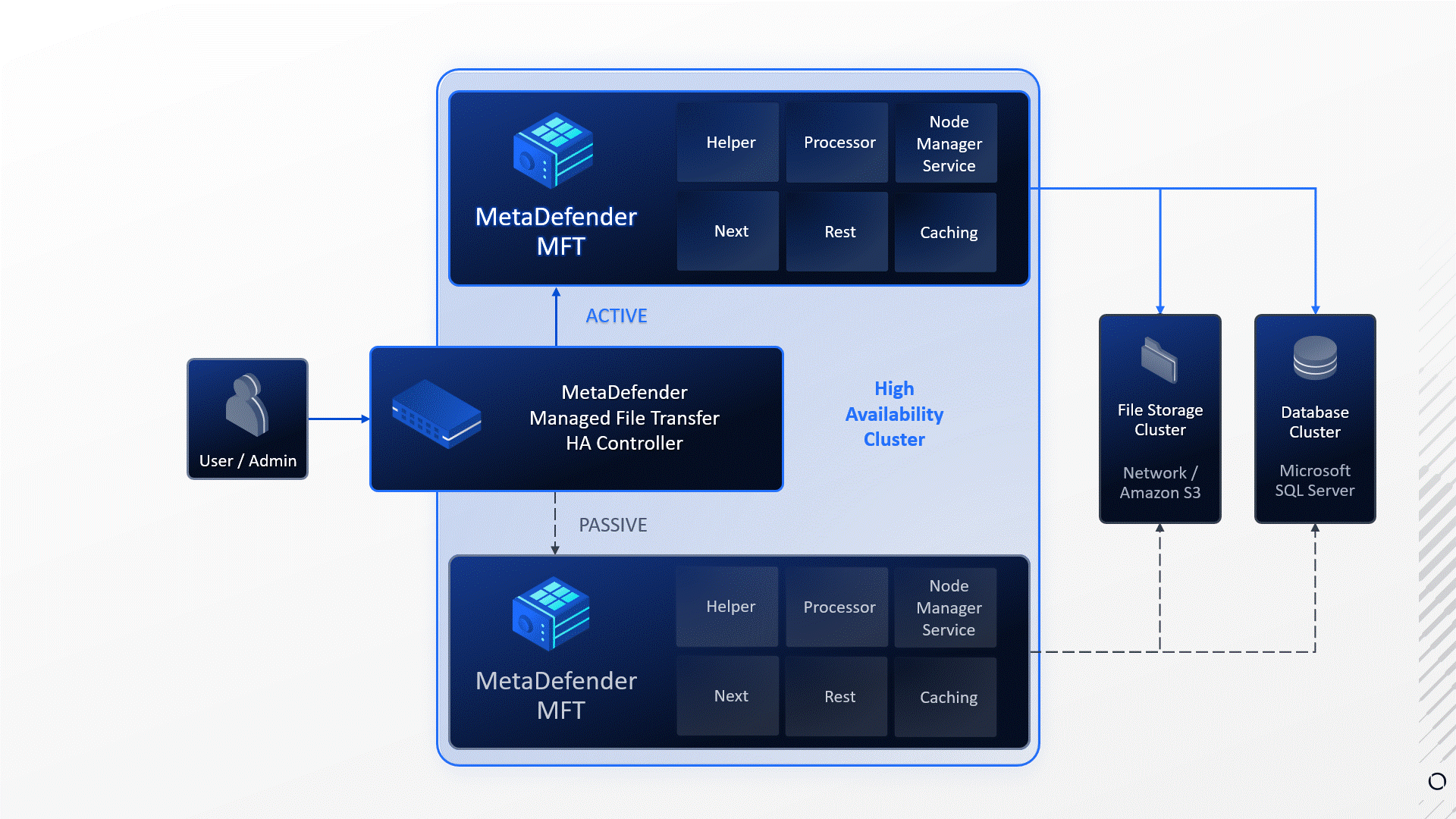
In this example:
- Service failure: The Processor service died unexpectedly.
- Failure detection: MetaDefender MFT HA Controller™ detected the service failure.
- Automatic Failover: Upon detecting the failure MetaDefender MFT HA Controller™ initiated a failover to the other node.
Machine Crash & Network Failure
If a MetaDefender® MFT instance either crashes or becomes completely unreachable due to host failure or network loss, the MetaDefender MFT HA Controller™ will detect the absence of health/heartbeat signals and trigger a failover to the alternate node. From the controller’s perspective, a service failure, full machine outage, or network failure all manifest as unreachable status and lead to the same recovery path.
Manually triggered failover
In certain maintenance or configuration scenarios (for example, updating certificates), you may need to trigger a manual failover. To do so you have to go to the currently active node and stop one of the application services in the Windows Service window.
Before manual failover
| Node | Status |
|---|---|
| Node1 | active |
| Node2 | passive |
- Stop one of the services on Node1, the best candidate is the REST service
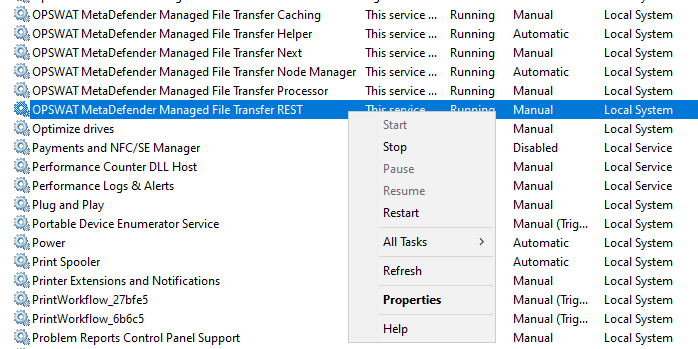
- Wait until Node1 is demoted as passive node (Helper and Node Manager will still be in Running status)

- Check Node2 and verify that all of the services are running there

After manual failover
| Node | Status |
|---|---|
| Node1 | passive |
| Node2 | active |