This guide provides detailed configuration options under Inventory > Modules > Utilities > Archive Extraction, enabling users to customize extraction settings effectively.
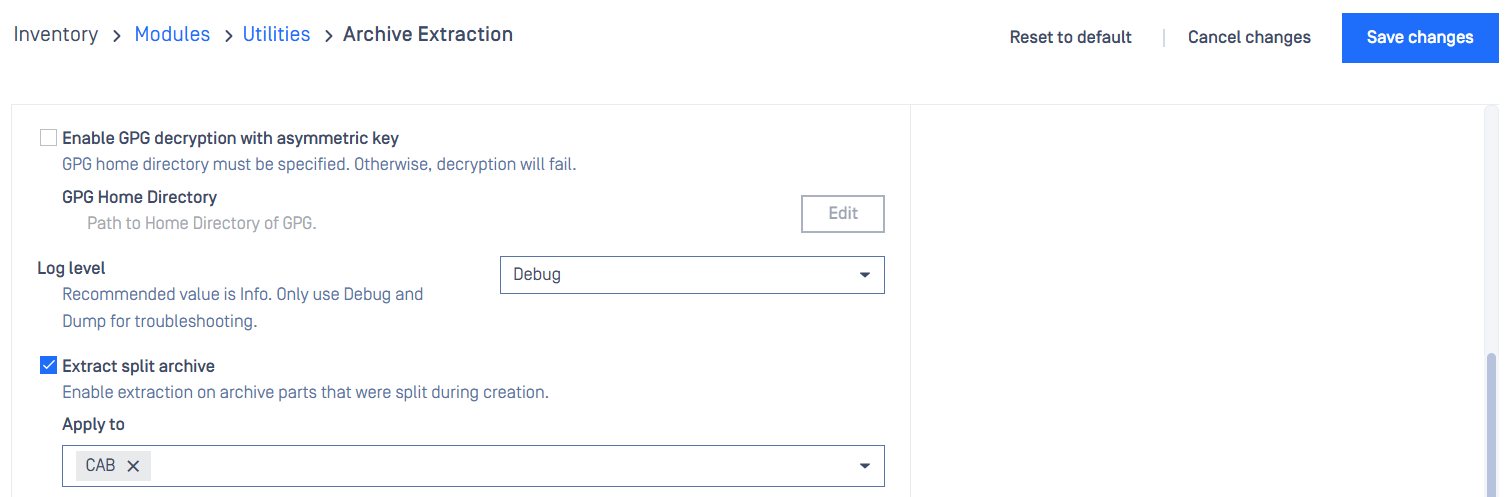
GPG decryption
See details of GPG Path and Enable GPG decryption with asymmetric key at Decrypt GPG files.
Log level
Allow users to configure log level.
Recommended value is Info. Only use Debug and Dump for troubleshooting.
Log Rotation is performed by compressing all the log files into an archive file when the current log size is greater than or equal to 512 MB and at least 30 minutes elapsed since the last rotation. Only 10 archived log files are kept.
Enforce HTML body content type matched
Enforce HTML body content to be matched as defined by content-type. Email body in HTML format mismatched with defined content-type will be replaced by simple HTML.
Extract split archive
Archive parts that were split during creation are distinguished from normal archive files and are not handled extraction by default due to possibly resulting in incomplete extracted entries.
This setting allows users to enable extraction on archive parts that were split during creation.
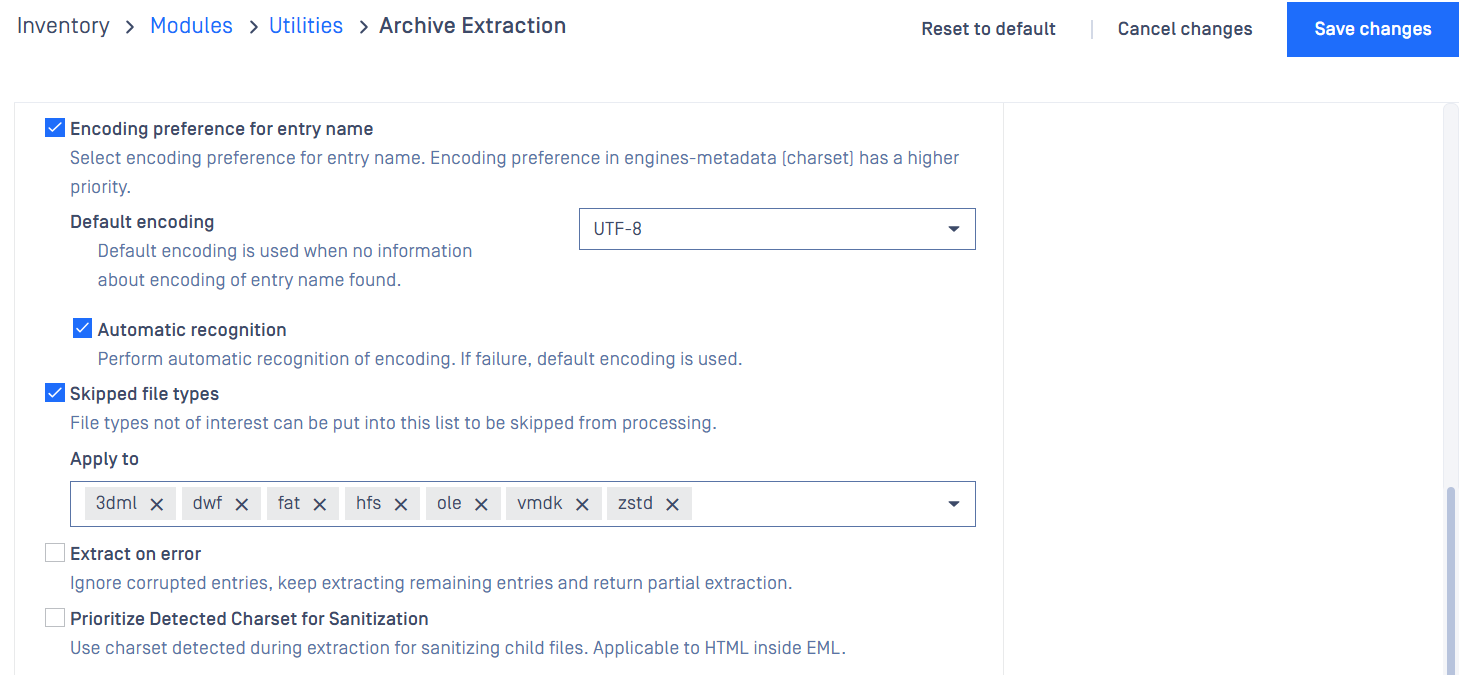
Encoding preference for entry name
Archive files like ZIP on users' systems may have diverse character encodings of child entry names. For example, some archive files have child entry name with character encoding UTF-8 while some others have those with Shift-JIS.
This setting allows users to select default character encoding and enable automatic recognition of character encoding for names of extracted entries.
Supported file types: ZIP, TAR, and CAB.
Character encoding preference in engines-metadata has a higher priority.
Default encoding
Select default character encoding, either UTF-8 or Shift-JIS.
Automatic recognition
Enable automatic recognition of character encoding to handle diverse character encodings of entry names.
The recognition is based on testing the possibility of child entry names against target encodings. It is not guaranteed always correct or determined. In case of undetermined, default encoding will be used.
Skipped file types
Some uncommon file types may be supported extraction per some special use cases. Extraction of these file types can be unnecessary or even cost extra processing time for common workflows.
File types not of interest can be put into this list to be skipped from processing. Customizing this setting can help balance efficiency with the flexibility to handle special requirements.
Newly supported file types are usually considered to be put in this list by default.
Extract on error
There are some archive files that are slightly corrupted. Default behavior returns failure for those immediately and may result in Blocked for the file.
In some workflows, users may expect to continue extraction, ignoring corrupted entries. This behavior helps maintain inspection of extractable entries.
This setting allows users to customize the engine to ignore corrupted entries, keep extracting remaining entries and return Partial extraction.
This setting will not change extraction result from failure to success. However, failure category could be changed. For details:
Corrupted Archivechanged toPartially Extracted ArchiveExtraction Errorchanged toPartially Extracted Archive
Prioritize Detected Charset for Sanitization
HTML email body that is extracted from an EML file may have charset incorrectly defined and differing from that defined in the EML structure which is a correct one. Charset extracted from the EML structure and specified in the HTML content as special hidden data can help direct the sanitization on the HTML content produce a valid output.
Use charset detected during extraction for sanitizing child files. Applicable to HTML inside EML.